
基本信息
原文标题:Fine-tuning Large Language Models for DGA and DNS Exfiltration Detection
原文作者:Md Abu Sayed, Asif Rahman, Christopher Kiekintveld, Sebastian García
作者单位:University of Texas at El Paso, El Paso, Texas 79968, USACTU - Czech Technical University, Prague, Czech Republic
关键词:Domain Generation Algorithm, DNS Exfiltration, Large Language Models, Natural Language Processing
原文链接:https://arxiv.org/pdf/2410.21723
开源代码链接:暂无
论文要点
论文简介:本文研究了 大语言模型(LLMs) 在 DGA(域名生成算法)和 DNS 数据泄露(DNS Exfiltration)检测中的应用。DGA 是恶意软件用来生成看似随机的域名与命令控制(C&C)服务器通信的技术,因其生成速度快,传统的检测方法难以有效应对。大语言模型因其在自然语言处理中的出色表现,成为了检测 DGA 和 DNS 数据泄露攻击的理想工具。通过微调现有的预训练 LLM,作者验证了该方法的有效性,并展示了其在处理 DGA 和 DNS 数据泄露检测任务时的强大能力。
研究目的:本研究的主要目的是评估大语言模型微调后的表现,特别是在 DGA 域名识别 和 DNS 数据泄露检测 方面。通过对59个真实世界的 DGA 恶意软件家族和正常域名数据的综合评估,作者验证了微调后的 LLM 相较于传统自然语言处理方法在未知 DGA 检测方面的显著优势。此外,研究还探讨了如何通过微调使模型适应网络安全任务,提升其在真实世界攻击检测中的准确性。
研究贡献:
-
提出了通过 微调大语言模型(LLM)来检测 DGA 和 DNS 数据泄露攻击的有效方法。
-
使用59种 DGA 恶意软件家族的数据集进行广泛评估,证明微调后的 LLM 超越了传统的自然语言处理方法,尤其在检测未知 DGA 上表现尤为出色。
-
在 DNS 数据泄露攻击检测中,微调后的模型表现优异,验证了其在提升网络安全防护措施方面的潜力。
引言
恶意软件(Malware)通过 命令与控制(C&C)服务器 向受感染系统发送指令并窃取数据,DGA 技术帮助恶意软件通过生成大量随机域名来规避检测,增加追踪和防御的难度。传统的 DNS 请求分析 是防止 DGA 和 C&C 通信的重要手段。现有的检测方法分为 基于签名的检测 和 基于异常的检测,但这些方法在面对大量动态生成的域名时往往效果有限。
机器学习技术,尤其是深度学习方法,逐渐成为 DGA 检测的主流方法。研究显示, 无特征方法(featureless methods)通过直接使用域名原始字符串并采用神经网络进行分类,表现出色。因此, 大语言模型(LLMs),凭借其在自动特征提取上的优势,成为了 DGA 检测的理想选择。微调大语言模型不仅能有效提高检测精度,还能应对复杂的网络攻击环境,如 未知 DGA 的检测。
本论文通过 微调大语言模型(LLMs),利用现有的 DGA 数据集进行实验,验证了其在 DGA 和 DNS 数据泄露检测任务中的应用潜力。
相关工作
DGA 检测研究经历了从简单的 CNN 模型到结合多模态信息和深度学习技术的复杂方法的演变。传统的 DGA 检测方法多使用 特征工程,如 n-gram 等统计特征,但随着 深度学习 的引入,研究者逐渐转向无特征方法,这类方法通过神经网络直接从数据中提取特征,具有更高的检测精度。
近年来,结合多模态信息(如文本和视觉数据)的方法得到了探索,并取得了一定成果。例如,Pei 等人提出的 TS-ASRCaps 框架通过深度学习自动提取文本和视觉数据的多模态特征,提高了 DGA 检测的准确性。而 Cucchiarelli 等人 则通过 2-gram 和 3-gram 词汇特征结合 Jaccard 指数 和 KL 散度,提出了一种新的基于词汇特征的 DGA 检测方法。
随着 DGA 检测技术的发展, DNS 数据泄露检测成为另一项重要的研究任务,尤其是在 企业网络安全中,针对 DNS 渠道的攻击越来越频繁。Jawad 等人开发的实时检测机制基于机器学习,通过对 DNS 查询数据的分析来检测泄露行为。
研究方法
为提升模型在 DGA 和 DNS 数据泄露检测中的表现,本文采用了 微调(fine-tuning) 预训练大语言模型的方法。通过微调,研究人员能够利用大规模数据和深度学习技术的优势,同时降低模型训练的计算成本。为此,本文采用了 参数高效微调(PEFT) 技术,如 低秩适应(LoRA) 和 量化 LoRA(QLoRA),减少了需要调整的参数数量,提高了训练效率。
在具体实现中,研究使用了多个预训练的 BERT、RoBERTa、LLAMA3 和 Zephyr 模型,并进行了针对 DGA 域名检测 和 DNS 数据泄露检测 的微调。模型训练过程中,目标从传统的下一个词预测任务转向了针对分类任务的优化,使得模型能够更好地适应 DGA 和 DNS 数据泄露的检测需求。
实验实现
本文的实验主要涉及两大任务:DGA 检测 和 DNS 数据泄露检测。在 DGA 检测 中,实验考虑了 二分类 和 多分类 两个设置,分别识别是否为恶意 DGA 域名,并进一步细分到特定的 DGA 类型。在 DNS 数据泄露检测 中,作者通过清洗和去重,确保了数据集的公正性,并评估了 BERT 和 Hybrid BERT 模型在检测 DNS 泄露攻击方面的表现。

在数据集选择上,本文使用了来自 Alexa、Bambenek Consulting 和 360 Lab 的多个数据集,结合正常域名和 DGA 数据进行训练和测试。
研究结果
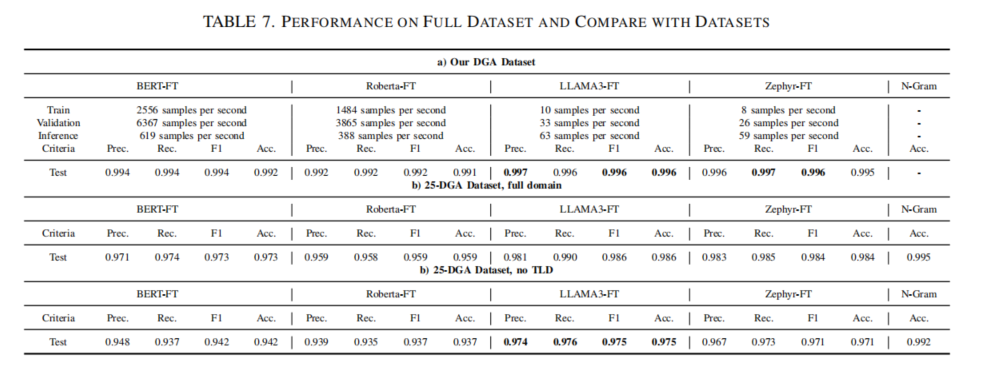
通过实验,作者验证了微调后的 LLAMA3-FT 模型在 DGA 检测 中的卓越表现,准确率达 98.6%。该模型在 已知 DGA 的二分类任务中超越了其他 LLM 模型,如 Zephyr-FT 和 BERT-FT。在 多分类 任务中,微调后的模型同样表现出色,能够准确识别出不同类型的 DGA 域名。
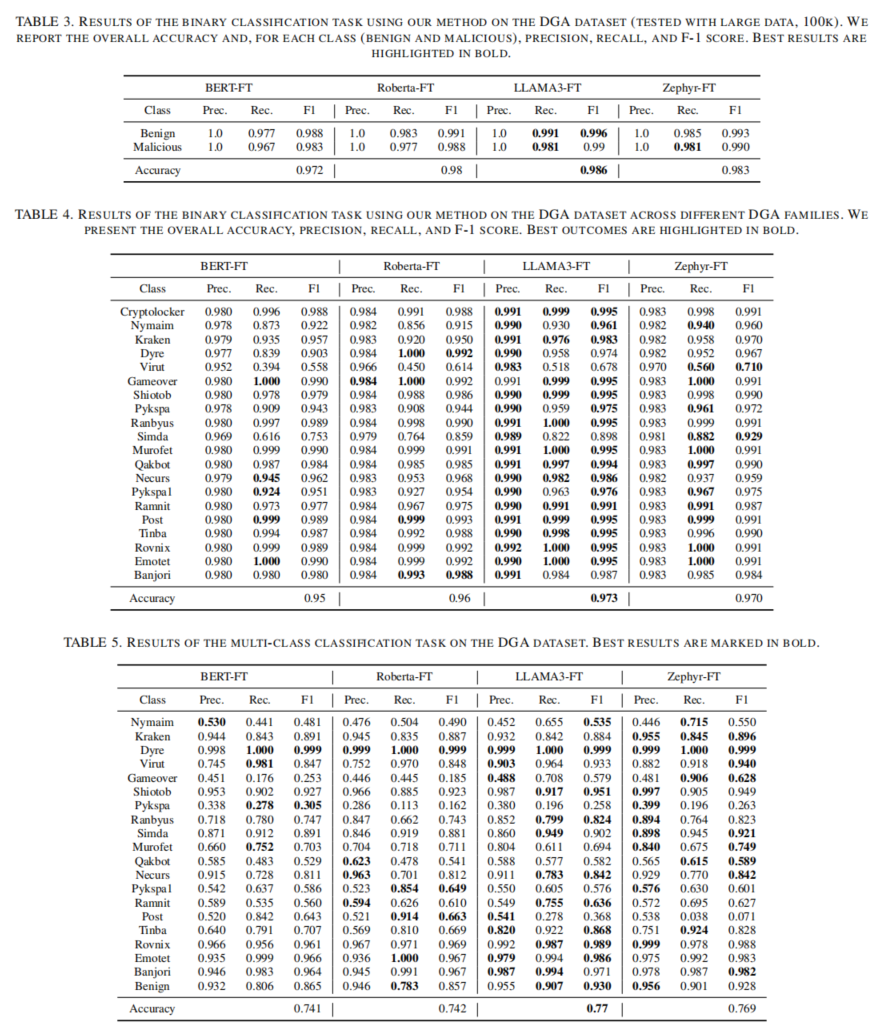
在 DNS 数据泄露检测 中,作者使用了 BERT 和 Hybrid BERT 模型进行测试,尽管在简单数据集上取得了 100% 的准确率,作者指出,过于简单的数据集可能导致过拟合现象,未来应使用更复杂的数据集以提高模型的鲁棒性。
论文结论
本文研究表明, 微调大语言模型(LLMs) 在 DGA 检测 和 DNS 数据泄露检测 中具有显著优势,尤其是在处理未知攻击时,表现出色。通过微调,模型不仅能够提高检测精度,还能有效应对复杂的网络安全威胁。然而,模型在 多分类任务 中仍然面临挑战,需要进一步优化。
总的来说,本文的工作为 大语言模型 在网络安全领域的应用提供了新的视角,并为未来的研究方向奠定了基础。
