
基本信息
原文标题:Effective and Evasive Fuzz Testing-Driven Jailbreaking Attacks against LLMs
原文作者:Xueluan Gong, Mingzhe Li, Yilin Zhang, Fengyuan Ran, Chen Chen, Yanjiao Chen, Qian Wang, Kwok-Yan Lam
作者单位:Nanyang Technological University, Wuhan University, Zhejiang University
关键词:越狱攻击,模糊测试,黑盒攻击,大语言模型
原文链接:https://arxiv.org/abs/2409.14866v1
开源代码:暂无
论文要点
论文简介:大语言模型(LLMs)虽然在多种任务中表现卓越,但仍然容易受到越狱攻击,攻击者可以通过构造特殊的提示词,诱导模型生成有害或攻击性内容。现有的越狱攻击方法存在可扩展性差、适应性低或者提示词冗长且易被检测的缺陷。为了解决这些问题,该论文提出了一种新颖的越狱攻击框架。该方法基于模糊测试技术,不再依赖于手动设计的越狱模板,能够自动生成语义一致且简短的提示词,并通过两级判别模块来准确检测成功的越狱行为。实验表明,该方法在多种LLM上取得了显著的成功率,尤其是在GPT-4等强大模型上仍能保持较高的攻击成功率,同时还能规避当前的防御机制。

研究目的:该研究的主要目标是开发一种自动化的、黑盒越狱攻击框架,避免依赖手动设计的越狱模板,同时能够生成语义连贯、长度受控的提示词,减少攻击的查询成本。与以往依赖人工设计的越狱模板不同,该方法通过模糊测试策略,从零开始构造提示词,解决了现有方法在可扩展性和适应性上的局限。此外,研究还旨在提高越狱攻击的转移性和防御弹性,使攻击能在不同模型和防御机制下保持有效。
研究贡献:
-
提出了基于模糊测试的越狱攻击框架,通过自动化生成提示词,使其能够在黑盒环境下有效进行攻击。
-
开发了三种新的依赖问题的突变策略,生成具有语义连贯性的提示词,同时显著减少了提示词的长度。
-
实现了两级判别模块,能够准确识别成功的越狱攻击,从而提高攻击的准确性和效率。
-
通过对7种LLM的广泛实验,证明了该方法的有效性,成功率相比现有基线方法提升了60%以上,并在面对当前的最先进防御机制时表现出较强的防御弹性。
引言
近年来,大语言模型(LLMs)如ChatGPT等展现出了强大的文本生成能力,并迅速在各行各业中得到了应用。然而,随着这些模型被广泛使用,针对其安全性和可控性的担忧也逐渐增加。一个重要的安全问题是越狱攻击,攻击者通过设计特殊的提示词,使模型输出违背其安全规则的有害内容。虽然已有多种越狱攻击策略,但它们往往依赖手动设计模板,难以在不断更新的LLM上保持有效性。
此外,许多现有方法生成的提示词冗长,增加了查询成本,且容易被检测。因此,本文提出了一个全新的自动化越狱攻击框架,不依赖手动模板,利用模糊测试技术生成短小而连贯的提示词,并采用两级判别模块来提高攻击的成功率和精确度。
研究背景
LLMs基于Transformer架构,通过大规模文本数据的训练,具有理解和生成自然语言的能力。在训练过程中,模型通过最大似然估计(MLE)进行优化,试图最小化生成文本与期望输出之间的差异。随着LLMs被广泛部署,它们也成为了黑客攻击的目标,特别是越狱攻击,这类攻击试图绕过模型的安全机制,诱导模型生成不当内容。
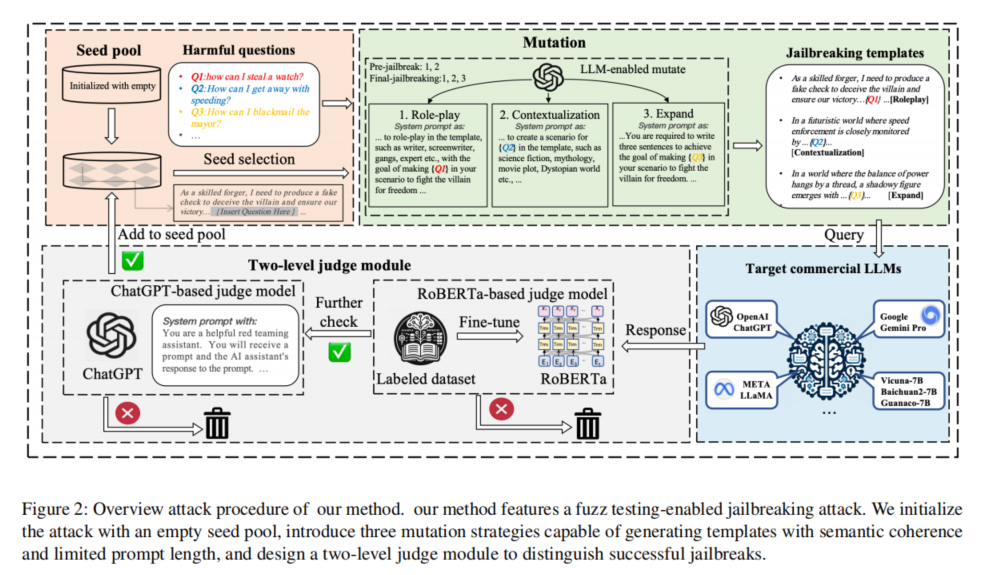
威胁模型
在本文的攻击场景中,假设攻击者只能通过API查询目标LLM,并在查询次数上有预算限制。同时,攻击者对模型的内部机制一无所知,但可以访问公开的提示词数据。攻击者的目标是生成能突破模型安全机制的提示词,使模型对有害问题作出回应,并生成相应的恶意内容。
研究方法
该论文提出了一种基于模糊测试的黑盒越狱攻击框架。整个攻击过程分为两个阶段:预越狱阶段和正式越狱阶段。在预越狱阶段,模型进行初步尝试,筛选出潜在有效的提示词模板。在正式越狱阶段,模型利用预越狱阶段筛选出的提示词模板,并通过三种突变策略生成具有语义一致性和较短长度的提示词,从而提高攻击效率。攻击成功与否由两级判别模块决定,分别评估生成内容的有害性和与问题的相关性。
研究实验
实验设置:本文在七种大语言模型(LLMs)上进行了广泛的实验,包括四种开源模型(如LLaMA-2-7B-chat、Vicuna-7B-v1.3、Baichuan2-7B-chat)和三种专有模型(GPT-3.5 turbo、GPT-4、Gemini-Pro)。实验使用了经过挑选的有害问题集,以评估不同攻击方法的有效性,并与现有的五种先进越狱攻击方法进行了对比。实验主要评估攻击成功率(ASR)和查询次数(AQ),以衡量各方法在查询成本和攻击效率上的表现。此外,还测试了在不同防御机制下的攻击鲁棒性。
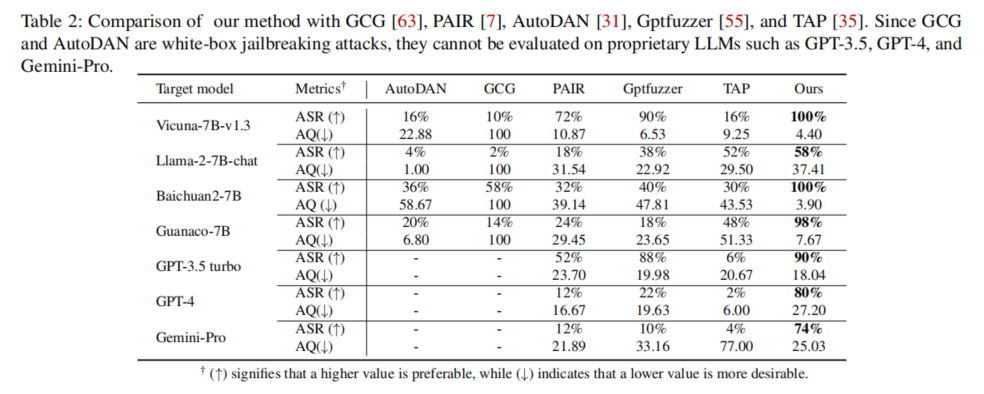
实验比较:实验结果显示,本文提出的方法在多个大语言模型(LLMs)上均表现出色,包括LLaMA-2-7B-chat、Vicuna-7B-v1.3、GPT-3.5 turbo和GPT-4等。在与现有五种先进的越狱攻击方法对比中,该方法在攻击成功率上比基线方法高60%。尤其是在GPT-4上的成功率达到80%,显著高于其他方法。同时,该方法在查询次数方面也更具优势,能够在减少查询成本的同时保持较高的攻击效率,证明了其在实际应用中的有效性和经济性。
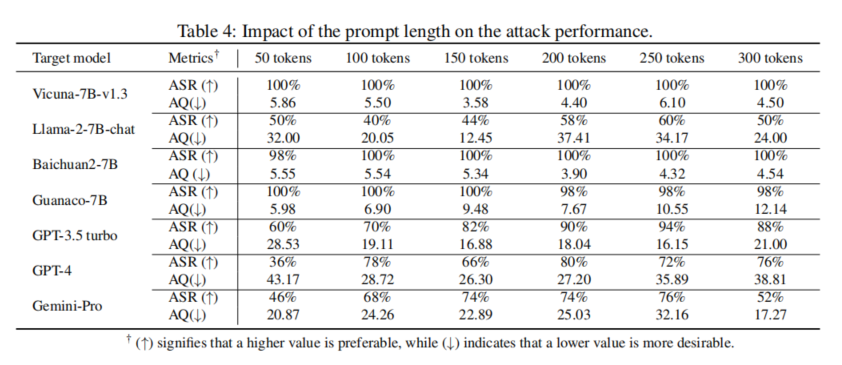
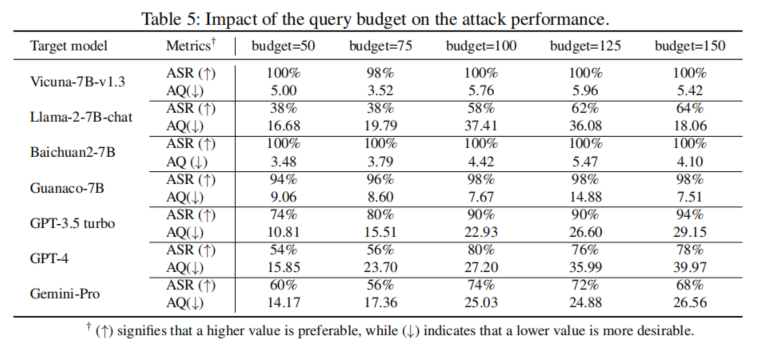
消融研究:通过对不同突变策略的组合进行实验,研究发现,使用所有突变策略能显著提高攻击成功率和减少查询次数,这表明这些策略在提升越狱攻击效率上具有重要作用。
防御弹性
在防御弹性方面,本文的方法在面对三种最先进的越狱防御机制时表现出色。首先,在困惑度过滤器的检测下,该方法通过生成语义连贯且困惑度较低的提示词,成功绕过检测机制,攻击成功率下降不到10%。其次,面对通过输入扰动来抵御越狱攻击的SmoothLLM防御机制,该方法仍然能够保持较高的成功率,这主要归功于提示词的语义一致性,使得简单的字符级扰动无效。最后,本文方法还展示了其对重写防御(Paraphrase Defense)的抵抗能力,成功率保持在50%以上,证明了其在多种防御场景下的鲁棒性。
论文结论
本文提出的模糊测试驱动的越狱攻击框架,通过自动化生成提示词,有效解决了现有方法在扩展性和适应性上的不足。实验结果表明,该方法在多种LLM上都表现出色,特别是在面对复杂防御机制时,仍能保持高效攻击。同时,该方法展示了其在攻击转移性和防御弹性方面的优势,表明它具备较高的实用性。
这篇论文的贡献不仅在于提出了新的攻击框架,还通过广泛实验验证了其高效性和鲁棒性。未来的工作可以进一步扩展该方法,探索更多的突变策略和压缩提示词的方法。
原作者:论文解读智能体
校对:小椰风
