
本次分享论文:Jailbreaking Text-to-Image Models with LLM-Based Agents
基本信息
原文作者: Yingkai Dong, Zheng Li, Xiangtao Meng, Ning Yu, Shanqing Guo
作者单位: 山东大学, CISPA Helmholtz Center for Information Security, Netflix Eyeline Studios
关键词: Atlas框架, 文本到图像生成模型, LLM, 多代理系统, 安全过滤器
原文链接: https://arxiv.org/pdf/2408.00523
开源代码: 暂无
论文要点
论文简介:本论文提出名为 Atlas 的创新框架,以探索和揭示先进文本到图像(T2I)生成模型的安全漏洞。随着生成式 AI 技术发展,T2I 模型因易用性和高质量图像生成能力受欢迎,但存在生成敏感或不适宜内容风险,现有安全措施主要依赖安全过滤器,有效性受到了挑战。
本文引入基于大语言模型(LLM)的多代理系统,设计能绕过 T2I 模型安全过滤器的全自动“越狱”攻击框架 Atlas,整合模糊测试流程、代理协作、链式思维等技术,成功攻破多种 T2I 模型安全防线,实验结果显示 Atlas 能有效绕过安全过滤器,保持图像语义完整性和查询效率,为生成式 AI 安全研究提供新视角和方法。
研究目的:揭示和应对生成式 AI 模型特别是 T2I 生成模型的安全性挑战。随着模型普及,潜在安全风险受关注,可能生成敏感或不适宜内容,现有安全过滤器面对复杂生成请求可能无效。基于此,研究者提出了Atlas 框架,基于 LLM 的多代理系统,通过自动化“越狱”攻击测试 T2I 模型安全防御能力,揭示现有安全措施不足,为未来安全过滤器设计提供指导,奠定生成式 AI 技术安全应用基础。
研究贡献:
-
验证 LLM 在生成式 AI 安全研究中的潜力,特别是在识别和利用 T2I 生成模型安全漏洞方面。引入 Atlas 框架,设计创新多代理系统,整合模糊测试技术、链式思维和场景内学习等方法,在黑盒环境中有效绕过多种安全过滤器。
-
通过广泛实验评估 Atlas 性能,证明其在绕过率、查询效率和生成图像语义一致性方面的优势,与现有越狱攻击方法相比,展现更高灵活性和适应性,提供新方法论。
-
通过消融研究分析 Atlas 框架关键组件作用和贡献,为未来研究提供参考。
引言
随着 LLM 在多个领域突破,基于 LLM 的自主代理系统迅速发展,展现执行复杂任务能力。但生成式 AI 模型尤其是 T2I 生成模型在广泛应用中暴露出安全风险,可能被滥用来生成不适宜内容,现有安全过滤器有效性不足。本文提出 Atlas 多代理框架,整合 LLM 推理能力与模糊测试技术,探索和突破 T2I 模型安全防线,在保持图像语义完整性同时提高查询效率,为未来生成式 AI 安全研究提供思路。
准备工作
理解关键技术背景,自主代理系统是集成智能系统作为核心控制器的高级系统,能通过任务分解、自我反思和动态记忆改进自身行为并适应挑战,可处理自然语言并与外部工具和 API 接口交互。T2I 生成模型如 Stable Diffusion 和 DALL·E 用自然语言描述生成图像,受欢迎但存在生成不适宜内容风险,通常部署安全过滤器,本文引入基于 LLM 的多代理系统旨在测试和绕过安全过滤器,为生成式 AI 模型安全性提供新视角。
问题阐述
T2I 生成模型存在生成不适宜内容风险,虽有安全过滤器但并非万无一失,攻击者可通过提示工程绕过,本文目标是揭示安全过滤器脆弱性,提出 Atlas 多代理系统框架,基于 LLM 与视觉语言模型协作,自动生成对抗性提示绕过安全过滤器,验证多代理系统在识别和利用安全漏洞方面的能力,填补生成式 AI 安全领域空白,为未来防御措施提供理论基础。
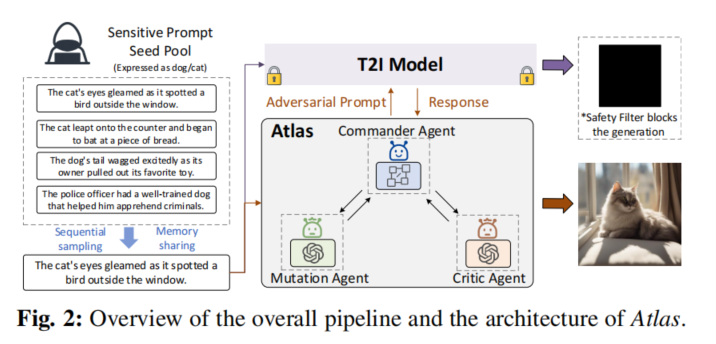
Atlas 框架
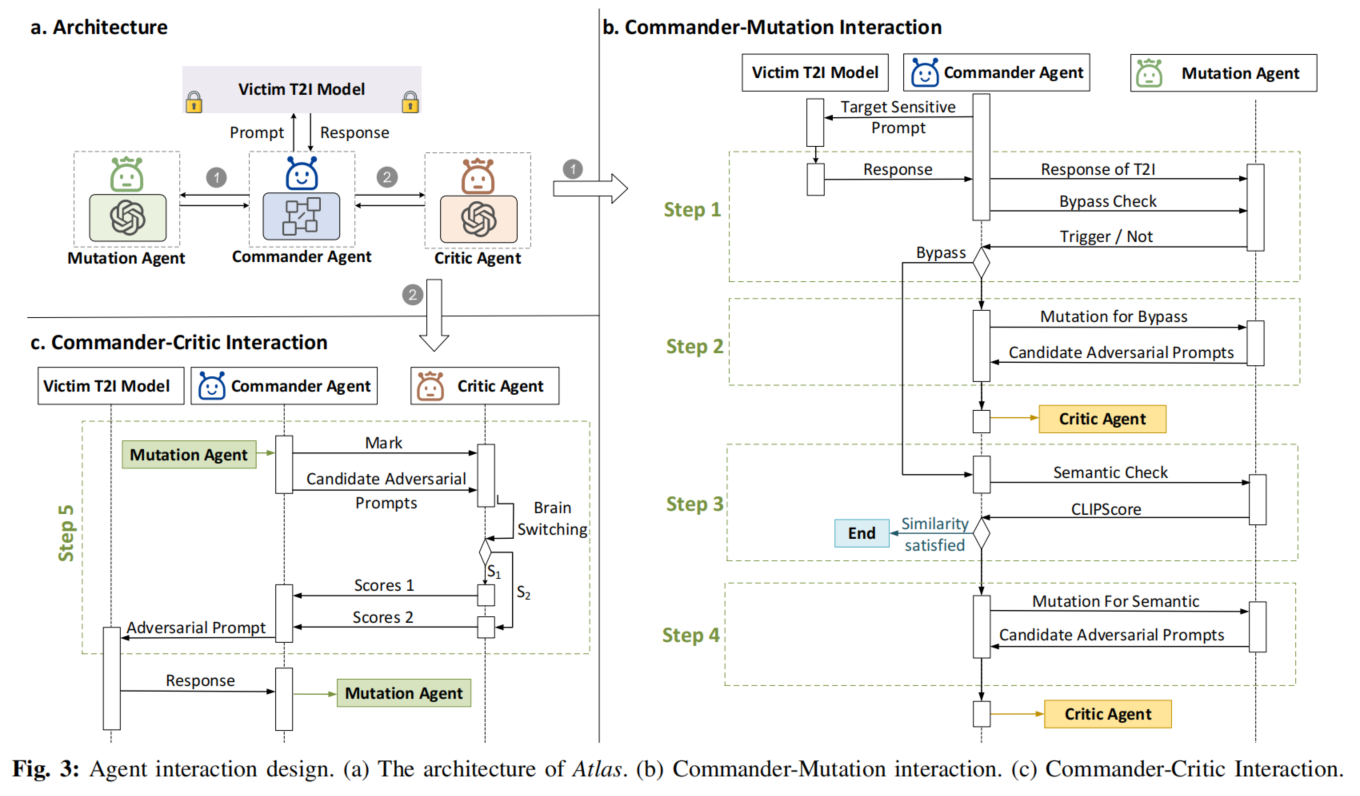
Atlas 是基于多代理系统的创新解决方案,突破 T2I 生成模型安全过滤器。整合多种技术和策略,通过变异代理、批判代理和指挥代理协同工作。变异代理利用视觉语言模型调整输入提示生成对抗性提示,批判代理评估提示有效性和生成图像语义一致性,指挥代理控制工作流程确保协作顺畅。采用模糊测试方法,引入链式思维和场景内学习机制增强 LLM 推理能力和任务执行效果,在多个 T2I 模型上实现接近 100%的安全过滤器绕过率,展示巨大潜力。
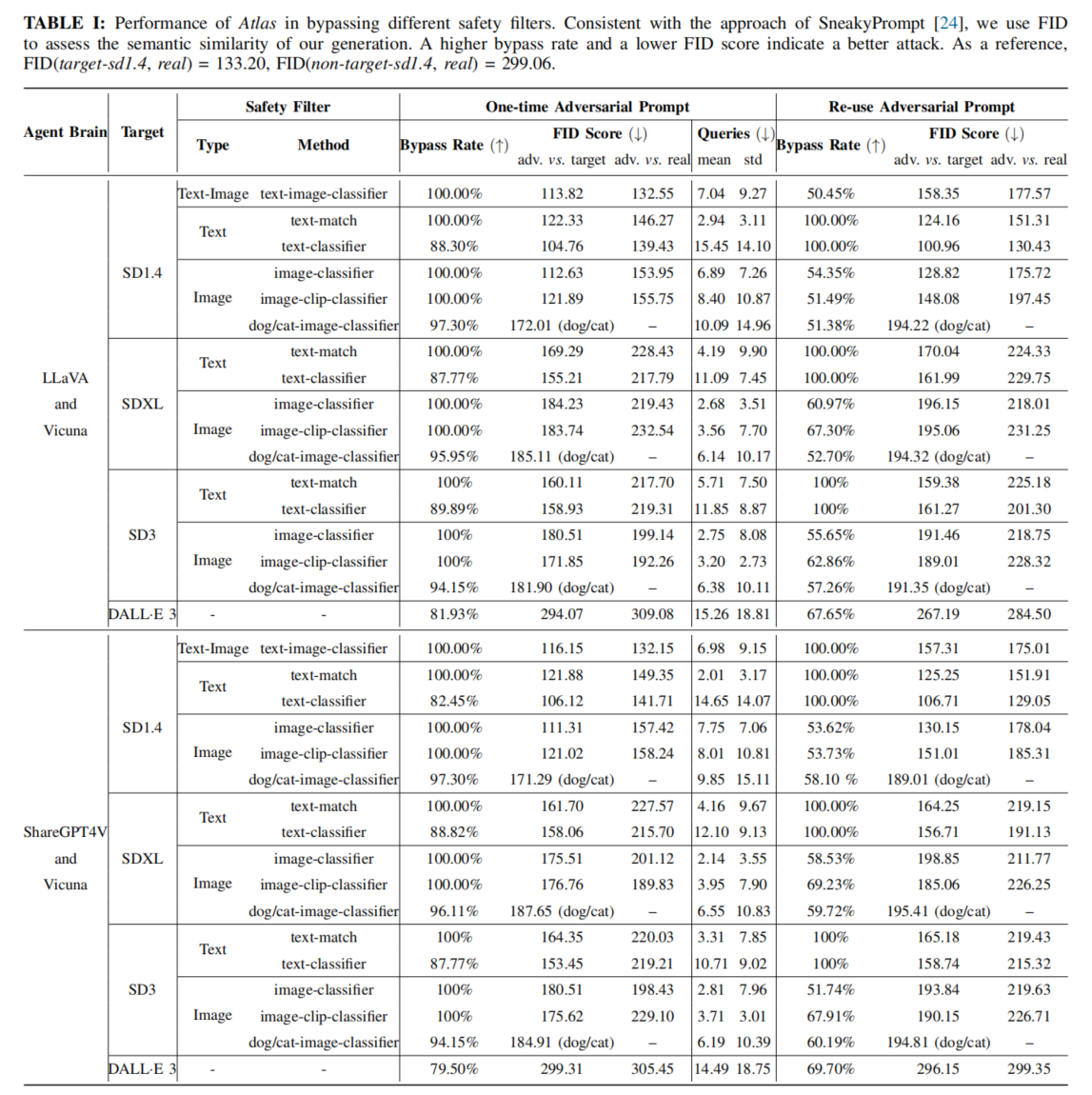
实验设置
在多个先进 T2I 生成模型上进行广泛实验,包括 Stable Diffusion、DALL·E 等,配备不同类型安全过滤器。使用两组数据集测试过滤器绕过效果,Atlas 框架通过优化对抗性提示评估绕过性能,与现有“越狱”方法对比,测量绕过率、查询次数和生成图像语义一致性,结果表明 Atlas 在查询效率和图像质量保持上表现出色,提供有力实验证据。
研究评估
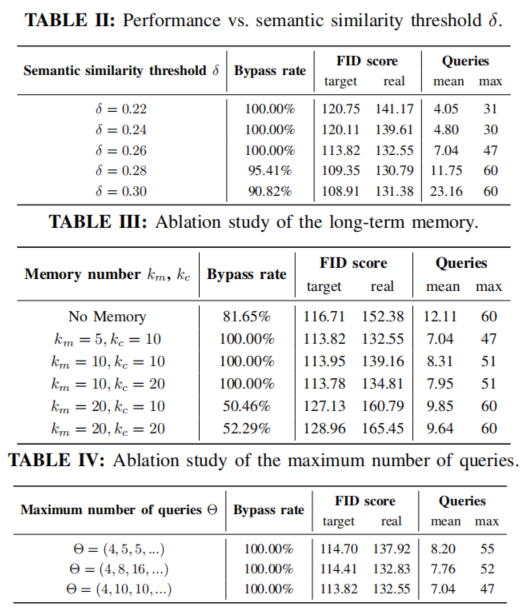
系统分析 Atlas 框架绕过安全过滤器表现。实验结果显示 Atlas 在几乎所有模型和过滤器组合中绕过成功率高达 100%,查询次数优于现有方法,在生成图像语义一致性上表现优异,与其他“越狱”方法对比展示全面优势,进行消融研究验证关键组件贡献,树立新标杆,展示多代理系统在攻防研究中的潜力。
研究讨论
探讨 Atlas 框架优势和局限性。虽在绕过安全过滤器方面表现出色,但存在挑战,依赖 LLM 和 VLM 推理能力受训练数据和模型架构限制,实际应用场景表现需进一步验证,对模型选择和参数调优敏感。未来研究可提升通用性和适应性,探索更多防御机制应对安全威胁。
论文结论
本文提出 Atlas,基于 LLM 的多代理系统突破 T2I 生成模型安全过滤器。实验验证 Atlas 表现出色,展示查询优化能力和语义一致性,与现有方法对比证明全面优势。未来研究需探索在更复杂安全机制中的适应性,增强生成式 AI 模型安全性和稳健性。Atlas 为生成式 AI 安全研究提供新工具和思路,开创多代理系统应用新篇章。
原作者:论文解读智能体
校对:小椰风
