
本次分享论文:Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models
基本信息
原文作者:Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, Lingming Zhang
作者单位:University of Illinois at Urbana-Champaign, University of Science and Technology of China
关键词:大语言模型, 模糊测试, 深度学习库, 缺陷检测
原文链接:https://arxiv.org/pdf/2212.14834
开源代码:暂无
论文要点
论文简介:研究团队开发了一种名为TitanFuzz的创新模糊测试方法,利用大语言模型(LLMs)自动生成和修改程序输入以测试深度学习库。该方法首先生成程序的初始种子,再应用进化算法逐步产生新的代码片段,从而显著提高了测试的深度和广度。TitanFuzz不仅提高了TensorFlow和PyTorch库的API及代码覆盖率,还成功检测出了多个之前未知的软件缺陷,显著增强了深度学习库的安全性和可靠性。
研究目的:本研究旨在解决传统模糊测试技术应用于深度学习库时的局限性,例如效率低下和覆盖范围不足。本文通过开发名为TitanFuzz的工具,利用大语言模型(LLM)生成和变异程序输入,从而增强了测试的广度和深度。这一方法有效地提升了深度学习库的缺陷检测能力,实现了对复杂API和代码的更全面覆盖。
研究贡献:
-
创新应用:首次将大语言模型(LLMs)应用于深度学习库的模糊测试中,这一实践展示了现代大语言模型在自动化生成和变异模糊测试方面的广泛潜力。该方法可扩展至多种软件系统的测试,例如编译器和数据库系统。
-
技术实现:我们开发了一个名为TitanFuzz的全自动模糊测试工具。该工具整合了生成型LLM(Codex)、填充型LLM(InCoder)和进化算法,不仅能生成高质量的种子输入,还能指导生成独特的库API调用和多样化的程序代码。
-
系统评估:我们对PyTorch和TensorFlow进行了广泛的评估。TitanFuzz在API和代码覆盖率上分别提高了24.09%和91.11%,以及50.84%和30.38%,成功地检测到了65个错误,其中41个是之前未知的。这一成果突显了LLMs在评估深度学习库安全性中的关键作用。
引言
随着深度学习库在众多关键领域的广泛应用,确保其稳定性和安全性显得尤为重要。然而,传统的模糊测试方法在应对这些库的高API复杂性和多样化输入时表现不佳。为此,我们引入了大语言模型(LLMs)作为测试工具,并开发了名为TitanFuzz的新型模糊测试方案。这一方案显著提高了代码和API覆盖率,有效增强了深度学习库缺陷的检测能力。此外,该方法不仅提升了测试效率,还扩大了模糊测试的适用范围。
研究背景
深度学习库,例如TensorFlow和PyTorch,已在图像处理和自然语言处理等领域中发挥核心作用。这些库的复杂性和普遍应用可能使内部错误导致严重后果。传统的模糊测试技术难以满足深度学习库对API和输入的复杂性要求,常因无法提供有效输入而未能覆盖复杂的代码路径,导致测试不全面。开发与这些高级功能匹配的新型测试方法,对提升软件的可靠性和安全性至关重要。
研究方法
在本研究中,我们开发了名为TitanFuzz的工具,该工具结合大语言模型(LLMs)来生成和优化程序输入。首先,利用生成型LLM(Codex)创建初步的种子程序;其次,通过结合填充型LLM(InCoder)和进化算法,指导程序输入的进一步变异和优化。这种方法不仅显著提升了代码和API的覆盖率,而且增强了对复杂深度学习库API使用情况的深入探索,有效地检测出潜在缺陷。
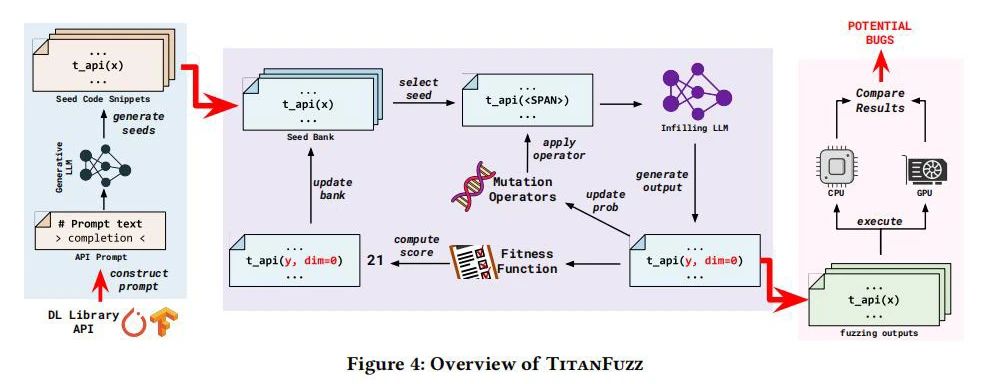
研究评估
为了评估TitanFuzz的性能,我们对两个主流深度学习库——TensorFlow和PyTorch——进行了全面的测试。通过将TitanFuzz与其他先进的模糊测试工具进行比较,结果显示在API和代码覆盖率方面TitanFuzz均有显著提升。具体而言,与传统工具相比,TitanFuzz在TensorFlow和PyTorch的API覆盖率分别提高了24.09%和91.11%,代码覆盖率分别提升了50.84%和30.38%。此外,TitanFuzz还成功检测到了65个错误,其中包括41个之前未发现的新错误,从而进一步证明了该方法的有效性和实用性。
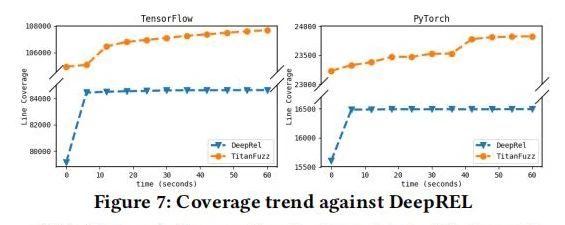
结果分析
TitanFuzz在深度学习库的模糊测试中展现了卓越性能,特别是在增强API和代码覆盖率方面。通过自动生成和优化测试代码,这一工具不仅扩大了测试的范围和深度,也高效地揭示了潜在的软件缺陷。测试结果表明,TitanFuzz在侦测新错误方面表现突出,发现的41个未知错误突显了其在实际应用中的关键价值。此外,这些成果展示了大语言模型在提升软件测试的质量与效率方面的巨大潜力。
论文结论
TitanFuzz的研究成果不仅提升了深度学习库模糊测试的效率和有效性,还展示了大语言模型(LLMs)在软件测试领域的广泛应用潜力。未来的研究可以探讨将此方法扩展到其他类型的软件库和系统,从而进一步拓宽其应用领域和增强其影响力。
原作者:论文解读智能体
校对:小椰风
