
本次分享论文:LLAMAFUZZ: Large Language Model Enhanced Greybox Fuzzing
基本信息
原文作者:Hongxiang Zhang, Yuyang Rong, Yifeng He, Hao Chen
作者单位:University of California, Davis
关键词:模糊测试,大语言模型,二进制结构化数据
原文链接: https://arxiv.org/pdf/2406.07714v2.pdf
开源代码:暂无
论文要点
论文简介:
灰盒模糊测试在揭示程序中的漏洞方面取得了成功。然而,随机变异策略限制了模糊测试器在处理结构化数据时的性能。专门的模糊测试器可以处理复杂的结构化数据,但需要额外的语法工作且吞吐量低。
本文探索了利用大语言模型(LLM)增强灰盒模糊测试的方法。利用LLM的预训练知识生成新的有效输入,并通过成对变异种子进一步微调模型以有效学习结构化格式和变异策略。LLM增强模糊测试器LLAMAFUZZ在标准bug基准测试Magma和各种实际程序上进行了实验,表现优于顶级竞争对手,平均多发现41个bug,并在所有实验中共发现了47个独特的bug。此外,LLAMAFUZZ在触发错误和达到错误方面展示了一致的性能。
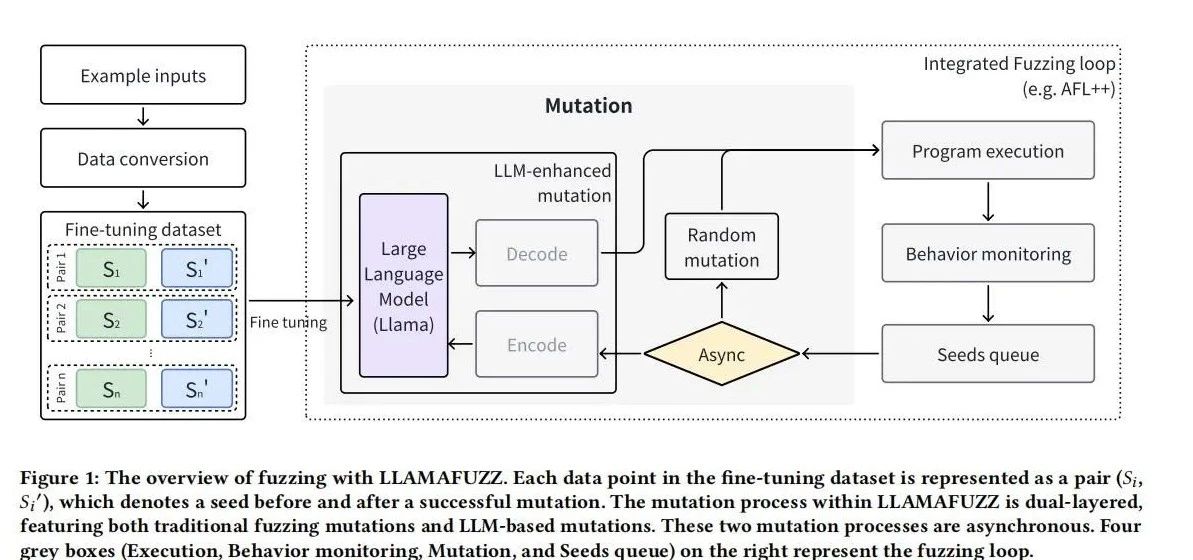
研究目的 :
本研究旨在利用大语言模型(LLM)提高灰盒模糊测试在处理结构化数据时的性能。传统的灰盒模糊测试在生成结构化数据时效率低下,而LLM具有数据转换和格式的预训练知识,能够生成新的有效输入。通过微调LLM使其学习结构化格式和变异策略,可以增强模糊测试器的性能,发现更多漏洞。
研究贡献 :
-
提出了一个LLM增强的变异策略,可以应用于二进制和文本数据格式。
-
提供了一种介于通用模糊测试器和专门模糊测试器之间的解决方案,能够学习结构化种子的模式并进行变异。
-
提供了实验证据,证明LLM可以增强变异过程,提高代码覆盖率。
-
通过实验解释了LLM如何增强模糊测试过程。
-
设计了一种轻量级的异步方法,利用LLM和模糊测试器的组合,使LLAMAFUZZ能够在单GPU或多GPU上轻松部署。
引言
模糊测试是一种自动化软件测试技术,通过生成测试种子来发现目标程序或应用程序中的漏洞。在过去几年中,灰盒模糊测试因其在发现新漏洞方面的有效性而备受关注。随着软件系统的复杂性不断增加,适应性测试输入的需求也变得越来越重要。随机变异虽然取得了一些成就,但在生成结构化数据方面却遇到了瓶颈。通用灰盒模糊测试器通过比特级变异实现高吞吐量,但当处理需要结构化输入的应用时,盲目的随机比特级变异往往会破坏数据格式的完整性,导致低效的种子。
为了加速这一过程,honggfuzz提出了共享文件语料库以支持多进程和多线程运行,从而提高了生成更多测试用例的吞吐量。然而,仅仅增加吞吐量和添加更多随机变异策略在处理结构化种子时会形成瓶颈。AFL++和honggfuzz需要大量尝试才能变异出有效的结构化种子。此外,使用随机策略的模糊测试器结果不稳定。为了缓解这种不确定性,需要进行多次重复实验以公平比较。我们提出使用大语言模型(LLM)来增强模糊测试中的变异过程,通过预训练LLM了解数据转换和格式信息来生成新的有效输入,并通过微调LLM学习特定的结构化种子模式和变异策略,从而在通用模糊测试器和专用模糊测试器之间找到平衡。
研究背景
灰盒模糊测试因其在发现许多实际程序中的漏洞方面的有效性而受到关注。然而,随着软件开发的复杂性增加,许多程序使用高度结构化的数据格式,这对传统的模糊测试技术提出了重大挑战。传统的模糊测试主要在比特级进行变异,需要大量尝试才能有效变异这些结构化数据。基于语法的模糊测试提供了一种通过人类指定语法生成良好结构化种子的方法,保证生成的输入在语法上是有效的,并具有多样性。然而,语法指导的模糊测试需要额外的领域知识,这限制了其广泛使用的可能性。
研究方法
LLAMAFUZZ的研究方法主要包括三个阶段:
-
微调准备:首先,我们收集了来自FuzzBench和AFL++实验的数据,创建了一个多样化的训练集。为了确保LLM能够处理各种数据格式,我们引入了一种数据转换方法,将二进制输入文件转换为统一的十六进制表示。这样做不仅使LLM能够理解并处理不同的数据格式,还确保了训练数据的多样性和有效性。
-
微调LLM进行变异:在这一阶段,我们对预训练的LLM进行微调,使其能够学习特定的结构化种子模式和变异策略。通过在结构化数据上进行监督微调,LLM能够调整其权重,从而准确地理解输入的语法并生成有效的变异模式。我们使用了分步提示的方法,引导LLM生成符合预期格式的变异输出。
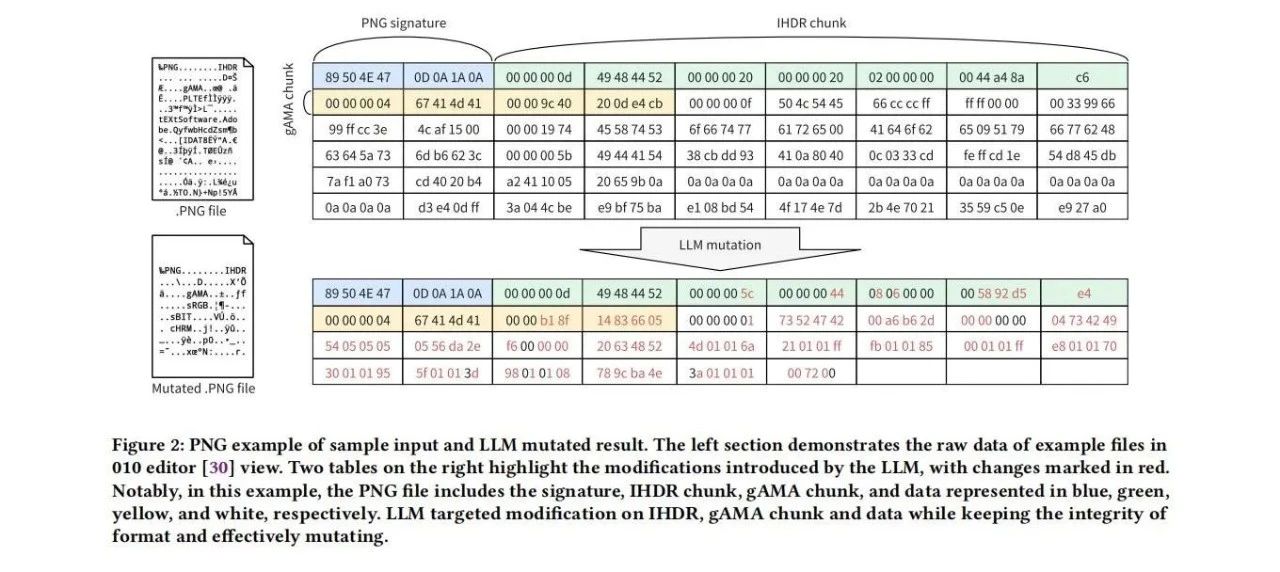
- 集成模糊测试器和LLM :为了解决LLM生成速度较慢与灰盒模糊测试高吞吐量之间的矛盾,我们设计了一种异步通信方法,将模糊测试器与LLM集成在一起。在这一过程中,当前种子被转换为十六进制表示后发送给LLM,LLM进行变异后将新的种子返回给模糊测试器。通过异步处理,确保模糊测试器在等待LLM生成变异种子的同时,能够继续高效地处理其他任务,从而提高整体测试效率。
研究实验
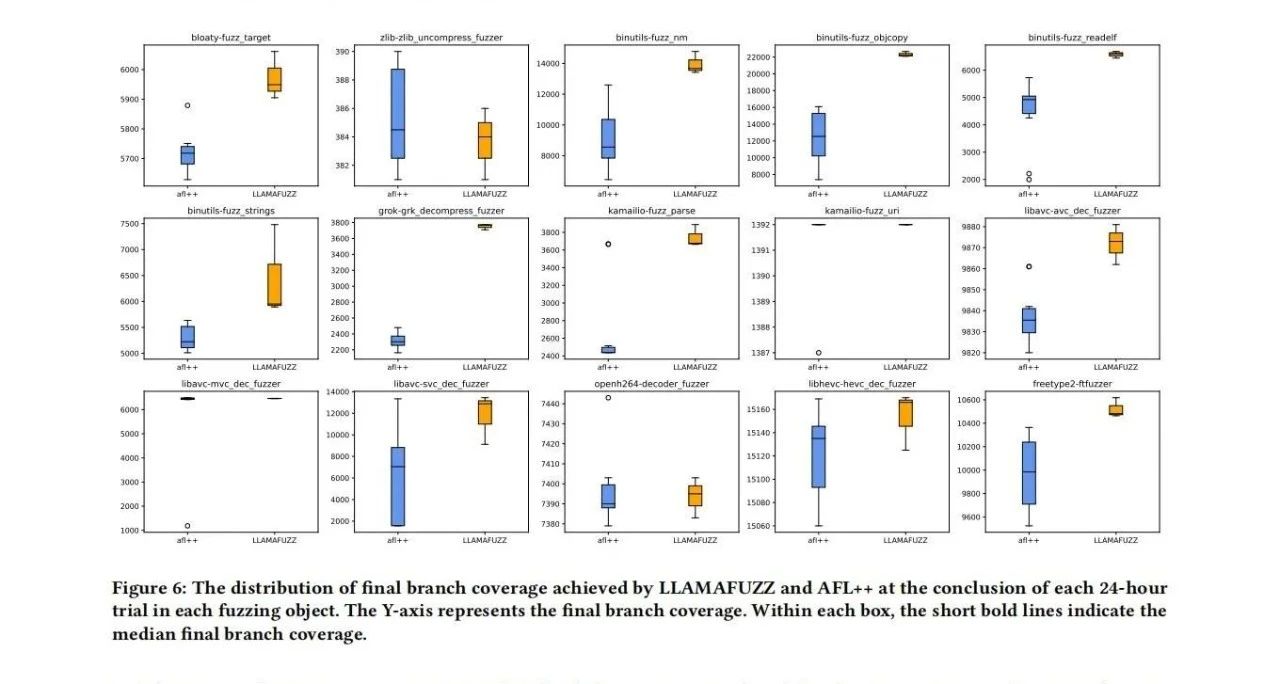
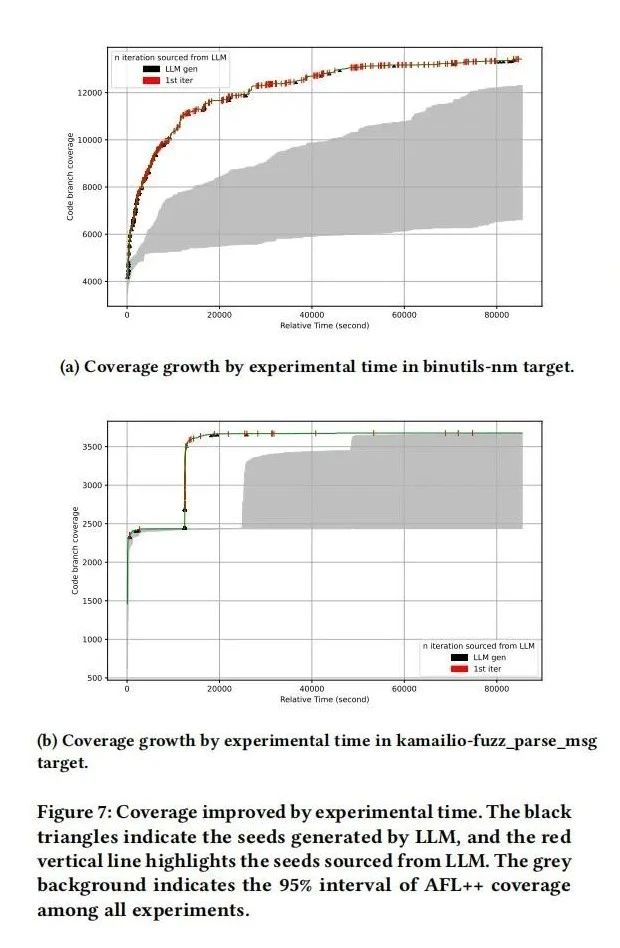
为了评估LLM在解决传统模糊测试在处理结构化数据方面的局限性,LLAMAFUZZ通过扩展AFL++实现,并在两个基准测试上进行了评估。实验包括在Magma基准测试和实际开源程序中的表现。结果显示,LLAMAFUZZ在bug发现数量和代码覆盖率方面均优于现有的模糊测试器,展示了其在处理结构化数据方面的优势。具体而言,LLAMAFUZZ在Magma基准测试中,平均比顶级竞争对手多发现41个bug,共发现47个独特bug。在实际开源程序测试中,LLAMAFUZZ在15个模糊测试目标中有10个显示出显著的代码覆盖率提升,平均提高27.19%。
相关工作
模糊测试是一种自动化随机软件测试技术,用于发现目标程序或应用程序中的漏洞。传统的模糊测试方法包括黑盒模糊测试、白盒模糊测试和灰盒模糊测试。黑盒模糊测试对程序结构不了解,主要通过随机生成测试输入实现高执行量,但效果有限。白盒模糊测试利用程序分析提高代码覆盖率,但耗时较长。灰盒模糊测试结合了白盒和黑盒模糊测试的优点,通过反馈机制生成更有价值的测试种子,提高测试效率。
论文结论
本文提出了一种利用大型语言模型(LLM)增强灰盒模糊测试的方法,通过预训练和微调LLM,使其能够有效地生成和变异结构化数据。实验结果表明,LLAMAFUZZ在bug发现数量和代码覆盖率方面均优于现有的模糊测试器,展示了其在处理结构化数据方面的优势。LLAMAFUZZ的成功验证了LLM在提高模糊测试效率和发现漏洞能力方面的潜力,具有广泛的应用前景。
原作者:论文解读智能体
校对:小椰风
