
本次分享论文:FuzzAug: Exploring Fuzzing as Data Augmentation for Neural Test Generation 基本信息
原文作者:Yifeng He, Jicheng Wang, Yuyang Rong, Hao Chen
作者单位:University of California, Davis
关键词:软件测试,数据增强,模糊测试,大语言模型,单元测试,测试生成
原文链接:https://arxiv.org/pdf/2406.08665
开源代码:暂未提供
论文要点
论文简介:在现代软件工程中,测试是确保程序可靠性的关键。然而,测试过程既重要又昂贵,促使自动化测试用例生成方法的兴起。传统的基于覆盖率的模糊测试和基于神经网络的测试生成各有优缺点。本文提出了一种名为FuzzAug的新型数据增强技术,结合模糊测试和大语言模型的优势,生成语法和语义上有效的多样化测试数据。实验结果表明,使用FuzzAug增强的数据集训练的模型,测试用例准确率提高了11%,分支覆盖率也显著提升。
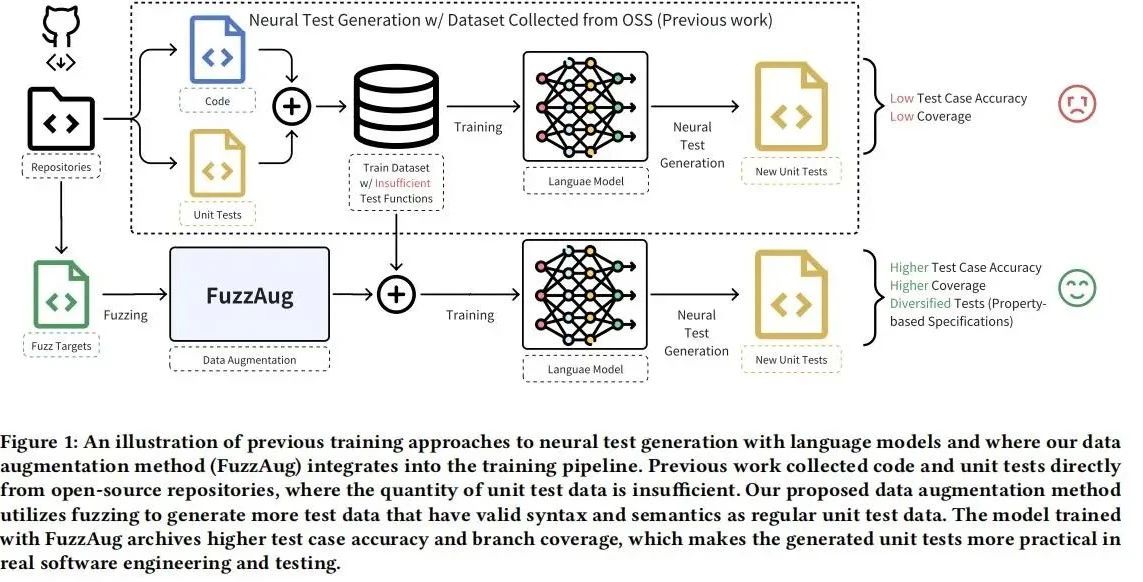
研究目的:本文旨在解决软件工程中单元测试不足的问题。单元测试是确保软件组件满足设计规范的重要手段,但编写高质量单元测试既困难又耗时。为了提高自动化测试生成的有效性和多样性,本文提出了FuzzAug技术,结合模糊测试和大语言模型,自动生成语义丰富且语法正确的测试数据。通过在现有数据集上应用FuzzAug,期望改善模型的测试生成性能,提升软件测试的覆盖率和准确性,从而助力开发人员更高效地进行软件验证。
研究贡献:
-
提出了一种新颖的数据增强方法FuzzAug,专为神经测试生成模型设计。该数据增强方法解决了代码库中测试代码不足和被测函数精确且多样化输入缺乏的问题。据悉,FuzzAug是第一个用于神经测试生成的数据增强方法。
-
构建并发布了一个新的Rust函数数据集,包含功能级别的代码-测试对,用于训练Rust程序的测试生成模型。在该数据集上应用了FuzzAug并发布了生成的增强数据集。
-
通过在数据集上训练自回归语言模型验证了FuzzAug的质量。添加FuzzAug后,模型性能的提升展示了在训练语料库中添加模糊测试增强测试函数的必要性和好处。
引言
在软件工程中,测试是确保大型软件应用程序质量和稳定的重要过程。单元测试是开发人员编写和执行的自我评估测试,旨在证明软件中的组件符合设计规范中的要求。然而,尽管测试的重要性,开发人员并不总是贡献新的测试,因为很难确定要测试的代码,将其隔离为单元,以及找到相关的输入。自动化单元测试生成是解决这些问题的方法,通过将所有函数视为被测单元(焦点函数),但生成的测试在可读性和相关输入输出对的正确性方面并不令人满意。
最近,利用机器学习模型特别是大语言模型(LLMs)的强大功能来缓解这些问题的研究逐渐兴起。尽管LLMs可以生成有意义的程序,但由于训练数据中单元测试数量和多样性不足,其在生成高质量测试方面的能力受到限制。本文提出了FuzzAug,一种结合模糊测试和LLMs优势的新颖数据增强技术,以改善单元测试生成的数量和多样性,从而提升软件测试的自动化水平。
FUZZAUG设计
FuzzAug旨在通过模糊测试增强神经测试生成模型的数据集。该方法通过随机生成有效输入来提高训练数据的多样性和覆盖率。首先,模糊测试生成具有程序行为特征的随机输入,确保数据在软件测试上下文中的有效性和意义。其次,通过代码转换,将模糊测试的目标转换为语法和语义正确的单元测试模板。这些模板在执行过程中通过模糊器验证其语法正确性,并保持测试函数的语义完整性。最终,FuzzAug生成的单元测试数据不仅丰富了训练集,还增强了模型处理多样化测试场景的能力,从而提高自动化测试生成的效果和覆盖率。
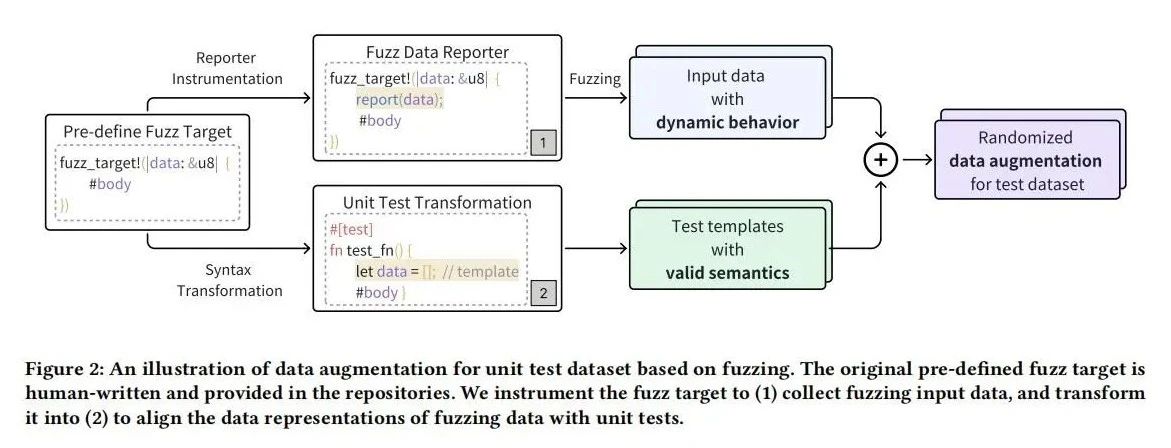
实验设置
数据收集:选择Rust语言进行研究,因为Rust项目结构化良好,便于构建和运行。从GitHub上收集了249个符合要求的Rust开源项目,确保这些项目活跃且包含单元测试和模糊测试目标。通过这些项目,收集了12452个函数调用和6481个单元测试对。为了增强数据,使用LLVM的libFuzzer工具对每个模糊测试目标进行模糊测试,生成了20504个增强后的测试对,最终构建了一个包含64579个测试对的综合数据集。
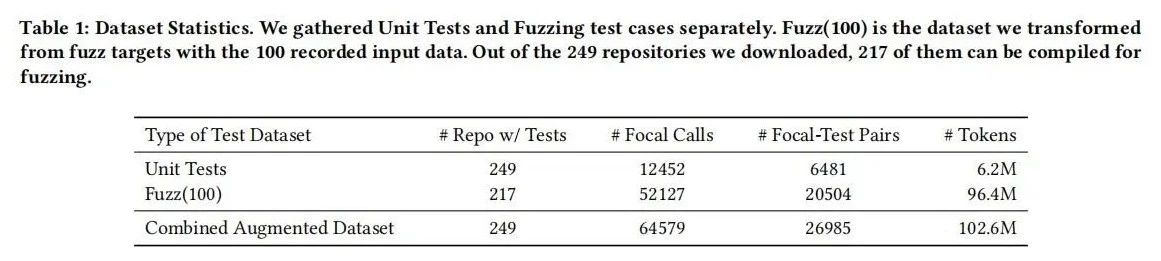
模型训练:选用了SantaCoder作为基础模型,这是一个最先进的开源代码生成模型,具有1.1B参数。训练过程中,采用因果语言建模(CLM)技术,对焦点函数和单元测试函数的组合进行训练。训练过程设置最大序列长度为2048,批量大小为16,学习率为5e-5,使用Adam优化器。首先用基础数据集训练模型,随后用增强后的数据集进行继续训练,确保模型能够充分学习到模糊测试增强带来的数据多样性和复杂性。
研究问题:本研究主要围绕以下两个问题展开:
-
FuzzAug是否能够提高生成测试用例的准确性?通过评估生成测试用例的正确性和编译率来验证这一点。
-
FuzzAug是否能够提高生成单元测试的实用性?通过评估生成的单元测试函数的分支覆盖率和通过率来验证这一点。此外,还考察了FuzzAug对不同模型的泛化能力,评估其在其他代码生成模型中的效果。
评估设置
HumanEval-X被选择作为评估基准,这是一套手工制作的多语言代码生成基准,包含164个不同的问题。根据每个问题的描述提示模型生成相应的单元测试函数。为了确保评估的公平性,所有实验中使用相同的提示方法和基本的后处理步骤,仅对生成的测试函数进行必要的语法修正。记录了生成测试用例的准确性、编译率、通过率和分支覆盖率,综合评估FuzzAug对测试生成性能的提升。
研究结果
实验结果显示,FuzzAug显著提升了生成测试用例的准确性和单元测试的实用性。与基线模型相比,使用FuzzAug训练的模型在测试用例准确率上提高了11%。此外,FuzzCoder在生成的单元测试函数中达到了更高的分支覆盖率,是未使用FuzzAug训练模型的两倍。FuzzAug对不同的代码生成模型同样有效,在其他模型(如CodeLlama)上也表现出色,进一步验证了其泛化能力和实用性。综合来看,FuzzAug通过增强训练数据的多样性和复杂性,显著提升了自动化测试生成的性能,为提高软件测试的覆盖率和准确性提供了有效的方法。
研究讨论
FuzzAug显著提升了神经测试生成模型的性能,通过引入多样化且有效的测试数据,改善了测试用例的准确性和单元测试的覆盖率。尽管如此,FuzzAug的实现依赖于预定义的模糊测试目标,这可能限制其在某些项目中的应用。此外,在生成长输入时,模型有时会消耗所有令牌限制,导致生成的测试函数无法编译。未来的研究可以进一步优化FuzzAug的方法,减少对预定义模糊目标的依赖,并改进模型在处理长输入时的效率。总体而言,FuzzAug在提升自动化测试生成的质量和实用性方面展现了巨大的潜力。
相关工作
模糊测试和神经测试生成是自动化软件测试的两个重要领域。模糊测试通过随机生成输入,探索程序的新路径,发现潜在漏洞。AFL++和libFuzzer是其中最著名的工具。神经测试生成利用大语言模型(如SantaCoder和CodeLlama)生成语义丰富的测试用例。此前的研究如UniTSyn和CAT-LM,通过收集和对齐代码和测试对,改进了测试生成模型的性能。然而,现有方法在处理测试数据不足和多样性方面仍存在局限性。FuzzAug结合了模糊测试和语言模型的优势,提出了一种新颖的数据增强方法,显著提升了测试生成的效果。
论文结论
本文提出的FuzzAug方法,通过结合模糊测试和大语言模型,有效解决了测试数据不足和多样性缺乏的问题。实验结果表明,使用FuzzAug增强的数据集训练的模型在测试用例准确性和单元测试覆盖率方面显著优于基线模型。FuzzAug不仅提高了神经测试生成的性能,还展示了良好的泛化能力,适用于不同的代码生成模型。未来的研究可以进一步优化此方法,扩大其应用范围。总体而言,FuzzAug为自动化软件测试生成提供了一种高效且实用的解决方案,具有重要的应用价值。
原作者:论文解读智能体
校对:小椰风